

" height="48px" id="vlIcIHuuL" width="48px"/></g></svg>)
Modern compute infrastructure is built around a fundamental assumption: to process data. You can encrypt data at rest and in transit. But the moment computation begins, the moment your backend actually runs your logic, the data exists in plaintext inside a trust boundary you don't fully control.
This is the data-in-use problem. And it's the gap that Multiparty Computation (MPC) closes at the architectural level.
The Trust Boundary Problem
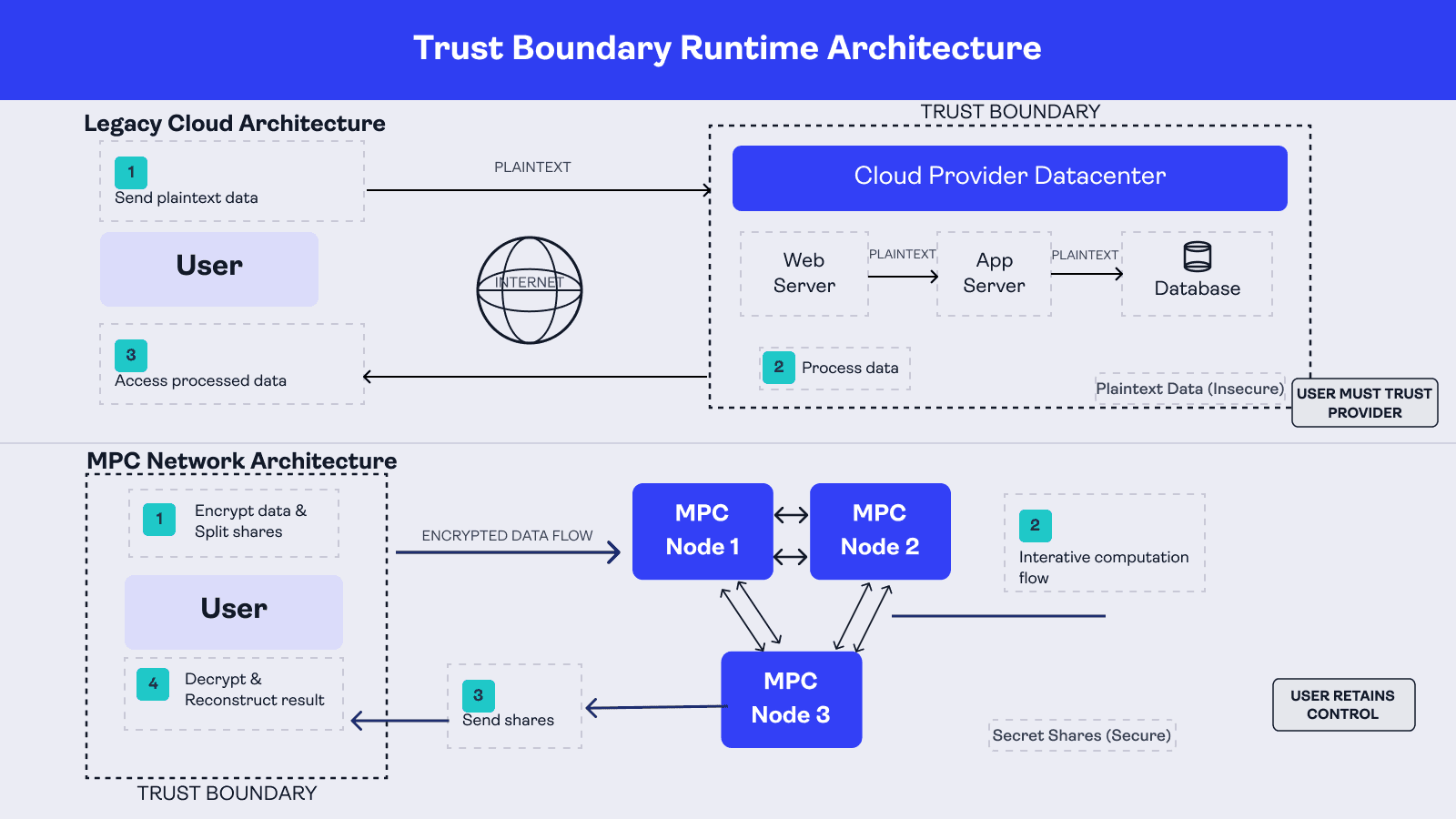
Most of the computation you execute is either performed on a single machine or in a data center.
For a single machine, you control what happens to the data and how it is used. When your program runs on a remote machine in a data center, you technically retain ownership of the data. However, you are now extending implicit trust to the provider's physical security measures, their operational controls, and their staff. When your program executes across multiple remote machines in several data centers, that trust compounds across every node in the chain.
The industry has spent twenty-odd years building vast cloud-based architectures on this model. Its tradeoffs has always been computing power and scalability in exchange for custody. In other words, you hand over your data, or your users' data, to make the system work.
MPC changes that tradeoff entirely.
How MPC Works
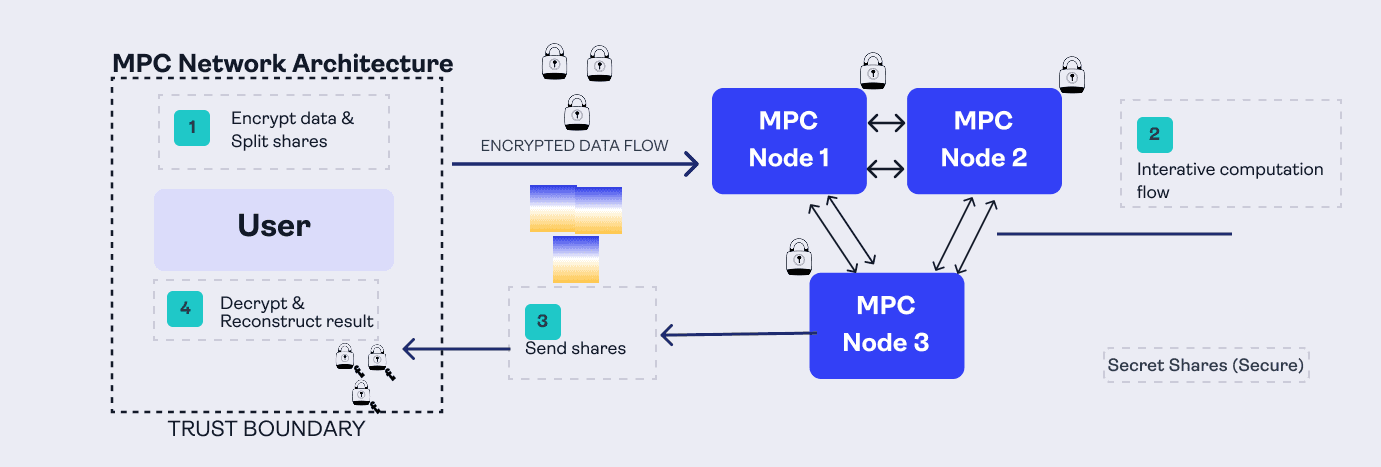
MPC accomplishes this through an interactive process between the client (who owns the data) and the distributed set of machines that will perform the computation. Here’s what that looks like in practice:
The client first prepares their data locally before it ever leaves their device. In an MPC system, that input is encrypted, secret-shared, or otherwise transformed into a protected form suitable for secure computation.
That protected input is then sent to the set of machines that will perform the computation. Because the data has already been prepared locally, the client does not hand over raw plaintext to the network.
Those machines have already been programmed with the function to compute. They run a secure protocol among themselves to evaluate that function on the protected inputs, without any single machine learning the underlying private data.
At the end of the protocol, the parties produce partial results that can be combined to reveal the final answer only to the authorized recipient.
That final result is reconstructed and used by the client or application, depending on how the system is designed.
Most importantly, no single machine ever needs full access to the user's underlying input for useful computation to occur. In a conventional backend, the service works by collecting plaintext data into the provider's trust boundary. In MPC, that trust is distributed across the protocol and the participating machines instead.
While MPC can involve many parties, many practical implementations simplify this to just two parties (2PC), with a client and a server, while maintaining the same security properties. This model is particularly significant because it maps the cryptographic process onto the same client-server architecture that defines the modern developer experience.

The Developer Experience
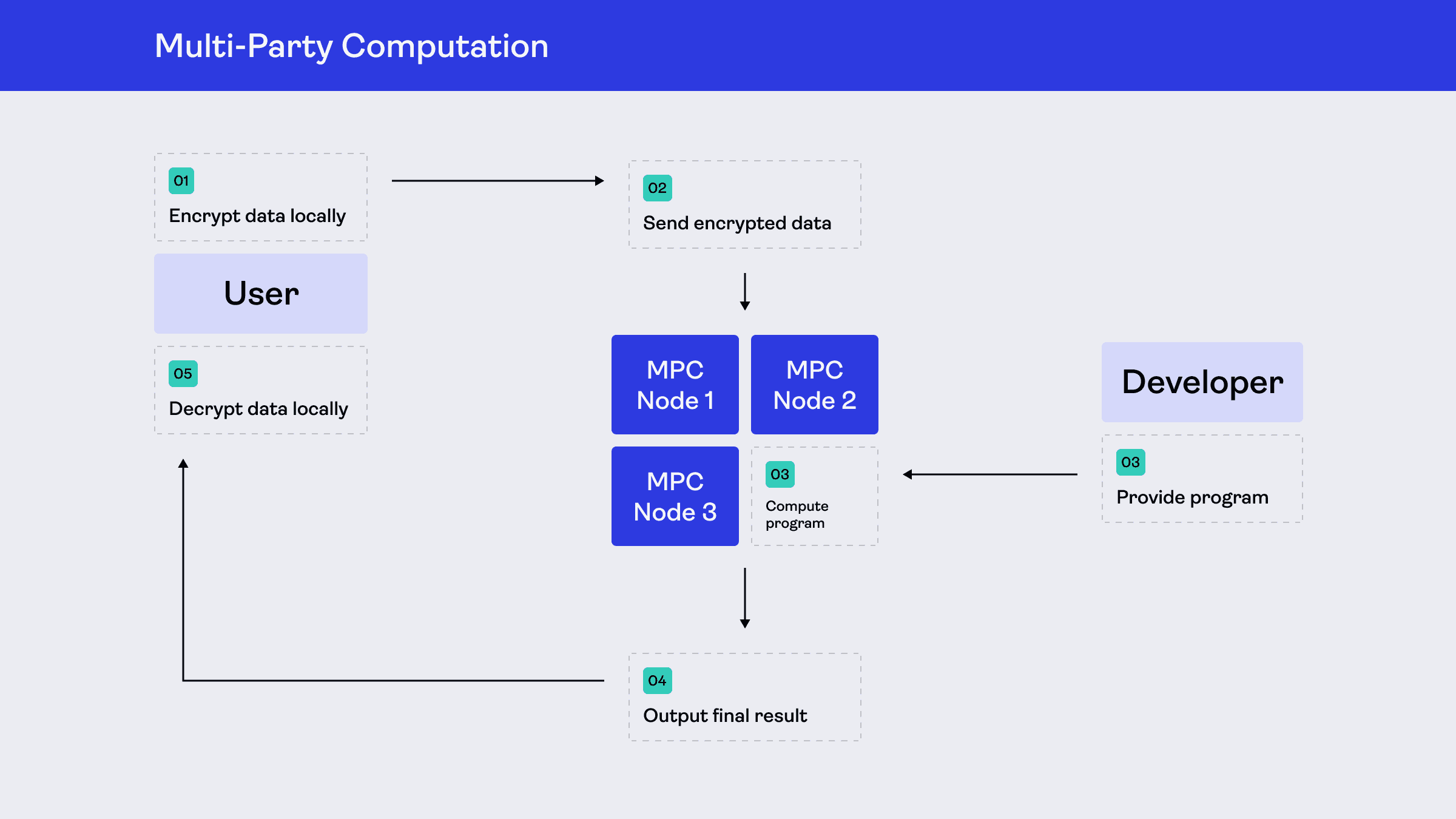
The architecture of an MPC network looks a lot like the kinds of distributed systems developers already work with on the web today. The difference is not that MPC introduces some completely foreign kind of backend, but how the computation is expressed and executed.
Instead of sending user data to a conventional backend where it exists in plaintext inside the provider's trust boundary, developers define the computation in a form that can run across multiple machines without any one machine learning the underlying private inputs.
In practice, this means writing the logic that will be executed by the MPC network itself, which typically uses an MPC-specific framework, language, or toolchain that compiles your program into a secure distributed execution flow. Essentially, you are defining a function that those machines will jointly evaluate while keeping user data protected throughout.
This does change the development model. You have to think differently about performance, state, data representation, and which parts of your application belong inside the MPC computation versus outside of it. There is also communication overhead to account for; the coordinated protocol between nodes has costs that conventional compute does not.
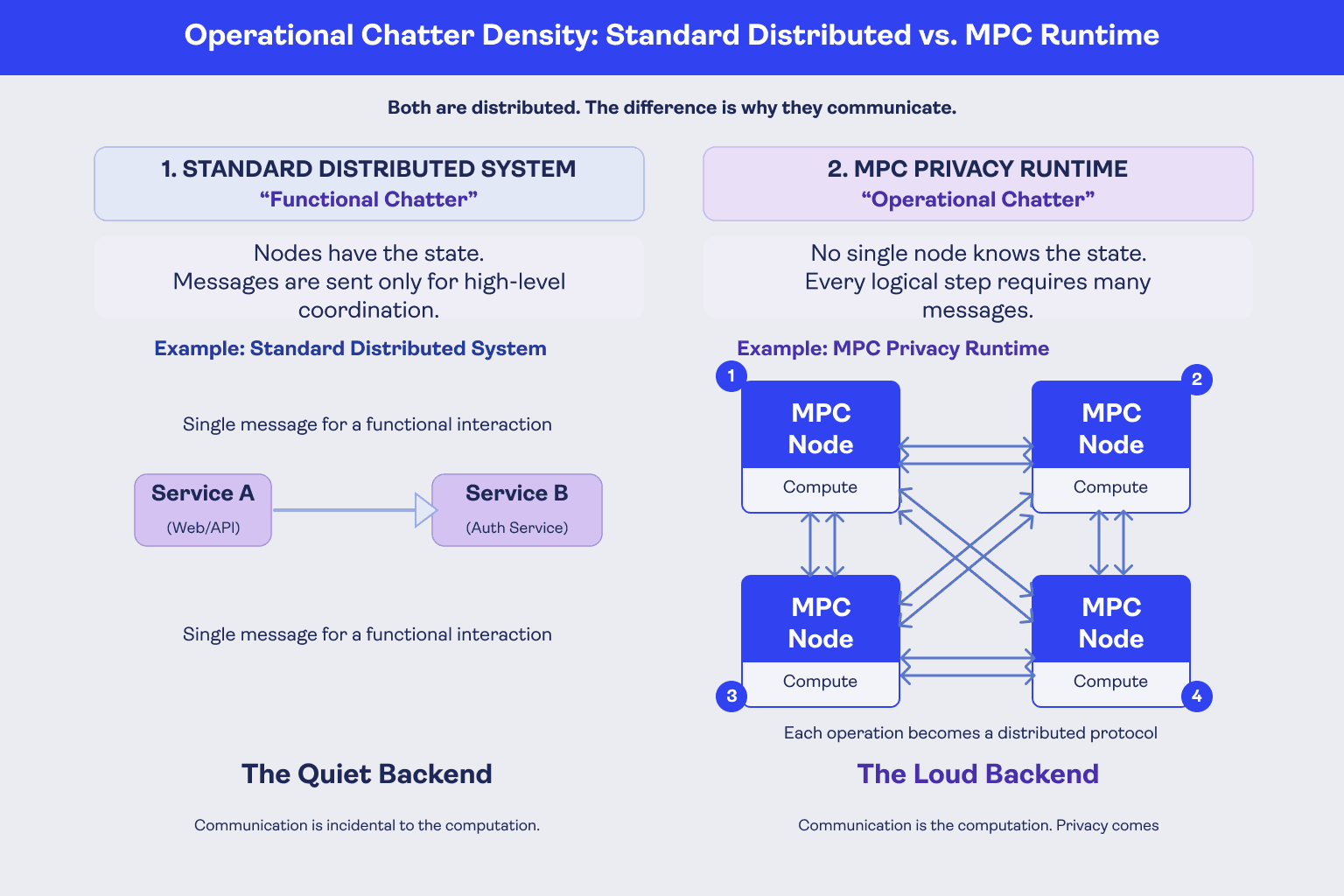
Ultimately, the payoff is tenfold: you can build applications that compute on sensitive user data without requiring your backend to collect and hold that data in plaintext.
That, in turn, reshapes the application architecture around it. If sensitive user data never needs to be centralized in plaintext on your servers, you can reduce what you need to store, replicate, secure, and account for from a compliance perspective.
Why this matters now
MPC is not new. The algorithmic foundations have been established for decades. What has changed is the gap between theory and production.
A combination of purpose-built runtimes, developer-facing toolchains, and improved protocol efficiency has brought MPC within reach of engineering teams who don't have cryptography expertise on staff. The question is no longer whether MPC works – it's whether you can integrate it into your stack without rebuilding your product around it. As users become increasingly aware of how their data is being used across their favorite internet services, the tradeoffs involved in building applications with MPC are becoming increasingly worthwhile.
At Stoffel Labs, we are closing that gap while building a privacy-first stack that enables you to build and ship applications while keeping your users safe.